
Kafka 동작 원리
https://huisam.tistory.com/entry/kafka
Apache Kafka - 메세지 브로커에 대해 알아보자
Kafka 메세지 브로커로 아주 많이 쓰이는 kafka 에 대해서 알아보자 💌 목차 Kafka 목차 아키텍처 Partition의 메세지 기록 방법 Replication 알아야될 정보들 참고 자료 아키텍처 전체적인 구성요소는 이
huisam.tistory.com
우리는 이전 시간에 kafka 에 대한 기본적인 동작 원리를 공부하였는데요.
이번에는 Consumer가 어떻게 Cosuming 하는지에 대해서 알아보도록 하겠습니다
물론, spirng-kafka 모듈을 사용한다는 가정하에 설명드리도록 하겠습니다.!
Consumer
우선, Kafka Consumer 가 뭘까요?
Kafka Consumer는 어떤 식으로 이루어져 있을까요?

뭐가 많아서 되게 어렵죠? ㅎㅎ
하나씩 살펴보도록 해봐요
| 구성 요소 | 역할 |
| ConsumerNetworkClient | Kafka Consumer의 모든 Network 통신을 담당 |
| SubscriptionState | Topic / Partition / Offset 정보를 저장하고 관리하는 담당 |
| ConsumerCoordinator | Consumer Reblance / Offset 초기화 및 커밋을 담당 |
| HeartBeatThread | 백그라운드에서 동작하며, Consumer가 살아있다고 Coordinator 에게 알려주는 담당 |
| Fetcher | 브로커로부터 데이터를 가져오는 담당 |
간략하게 정리된 책임들은 위 표와 같은데요.ㅎㅎ
디테일한 동작 설명은 궁금하신 분들만 참고하시면 될 것 같아요
개인적으로 제가 생각하기에 여기서 가장 중요한 부분은 바로, Fetcher, HeartBeatThread 인데요.
실제로 Kafka 를 운영하기 위해서는 어떤 식으로 Consumer들이 살아있는지, 동작원리를 알아볼 필요성이 있습니다.
왜냐하면, 새로운 Application을 배포하게 되면, 기존에 돌던 Consumer는 죽고, 새로운 Consumer들이 뜨게 되기 때문이죠.
Fetcher
쉽게 설명하면 Kafka topic에 있는 데이터들을 가져오는 것입니다.

그림에서도 볼 수 있듯이 consumer 가 얼만큼의 데이터를 가져올 것인지
( max.partition.fetch.bytes & fetch.min.bytes ) 를 설정하여 데이터를 가져오게 됩니다
fetch.min.bytes의 기본설정은 1byte 이며
max.partition.fetch.bytes 의 기본 설정은 1mebibytes 이며 약 1.048MB 입니다.
데이터 Size 와 같이 중요한 것이 바로 데이터를 가져오는 Record의 개수인데요
바로 max.poll.records 의 설정한 값만큼 record 를 가져오게 됩니다. ( default는 500개 )
그렇다면, 신뢰성 있고 주기적인 polling을 하기 위해서는 어떻게 해야될까요?
바로, max.poll.records 를 1 로 하는 것입니다
왜 그런지에 대해서는 polling 동작과 Consumer 가 살아있음을 알리는 HeartBeat 에 대해서 알아볼 필요가 있는데요.
바로 들어가보도록 하겠습니다.
HeartBeatThread
앞서 설명하였듯이 HeartBeatThread 는 Background 에서 동작하며,
Coordinator에게 살아있음을 알린다고 하였는데요.
이전에는 HeartBeatThread가 없어서 데이터 프로세싱 기반하는 것으로 Kafka consumer가
살아있고, 죽음을 판단하였는데요.
데이터 프로세싱과 Health Check 를 같이하니, 데이터 프로세싱이 길어지면 Consumer가 살았는지 죽었는지 즉각 확인할 수 없는 이슈 때문에 해결책으로 별도의 Thread 를 유지하기로 판단하였습니다.
가장 중요한 핵심은, 데이터를 프로세싱 하는 부분과 Consumer가 생존함을 알리는 부분을 분리하였다고 보시면 됩니다.
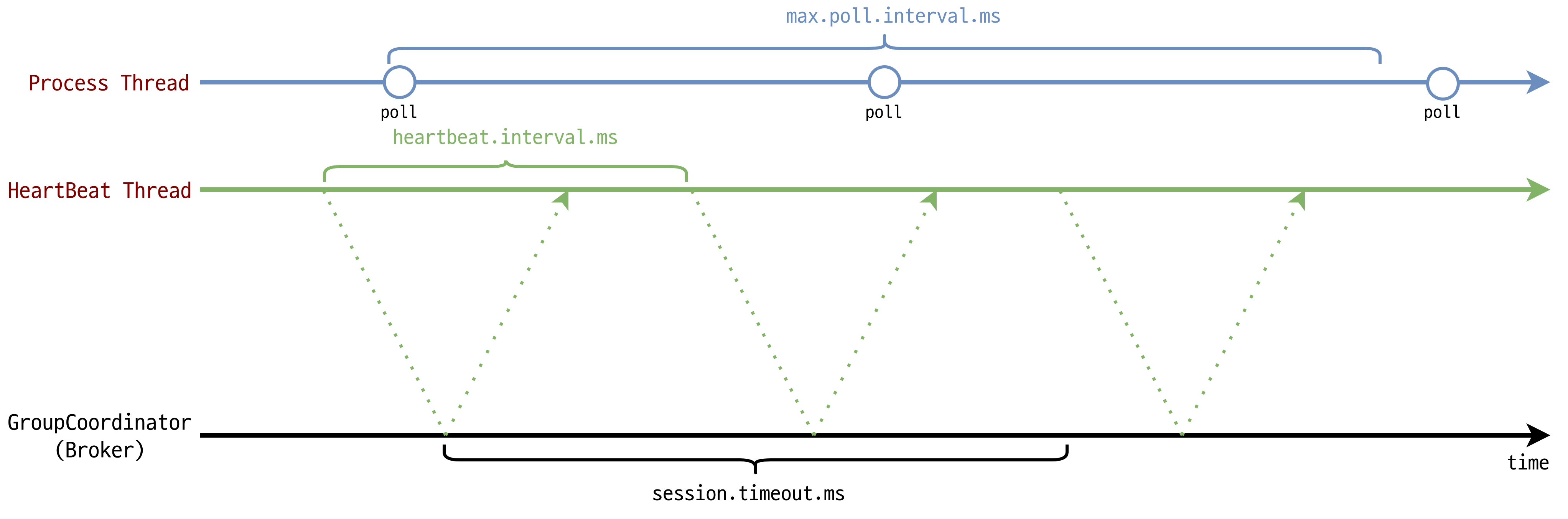
즉 polling interval 과 heartbeat interval 을 분리한 것을 볼 수 있죠.
| 옵션 | 정책 |
| max.poll.interval.ms ( default = 300000ms = 5분 ) |
해당 시간동안 poll 메서드가 호출되어야 한다. 만일, 해당 시간 내에 poll이 호출되지 않으면 Group에서 제외된다. HeartBeat 쓰레드가 poll 호출 간격을 측정하게 된다 |
| heartbeat.interval.ms ( default = 3000ms = 3초 ) |
해당 주기동안 HeartBeat를 Group Coordinator 로 전송한다. 일반적으로 session.timeout.ms 의 1/3 로 활용한다 ( session.timeout 보다 consumer는 Group에 포함될 수 없다 ) |
| session.timeout.ms ( default = 10000ms = 10초 ) |
해당 시간동안 HeartBeat이 도착하지 않으면 Group Coordinator 는 해당 Consumer를 Group 에서 제외한다 |
헛 그러면 우리는 위에서 polling 하는 record 의 수를 조절하는 옵션을 소개했는데요.
그렇다면, max.poll.records 를 1로하는 것이 왜 올바를까요?
바로 max.poll.interval 에 영향을 미치는 것이 바로 max.poll.records 이기 때문입니다.
일반적으로 polling 하는 데이터 프로세싱 과정(Appication 에서 프로세싱) 에서 로직문제로 지연이 발생한다면
poll.interval 도 자연스럽게 길어질 수 밖에 없는데요.
여기서 record의 수만큼 지연시간이 늘어나기 때문입니다
그러면 Application은 정상적으로 살아 있는데, Consumer가 제대로 consuming 하지 못하여
Kafka Record가 consuming이 안되는 장애를 맞이할 수도 있습니다.
즉, max.poll.records가 단순히 record 를 많이 처리하게 하는 설정이구나
하고 그냥 접근한다면 정말 큰일난다는 것입니다
설명중에 Group 이라는 용어가 나오게 되는데요.
Kafka Consumer들은 혼자가 아닌 여러 개의 Consumer들로 이루어진 Group 단위로 consuming 하게 됩니다.
Group?
먼저 Group 이라는 개념에 대해 알아야 되는데요.
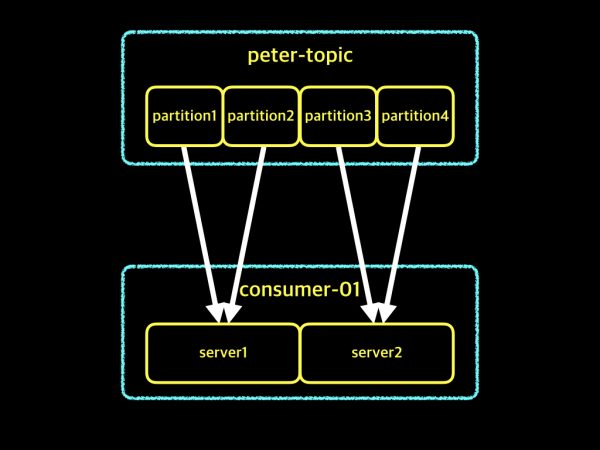
하나의 Topic 에 대해서 여러의 partition을 consuming 하는 집단이 바로 Group 입니다.
그렇다면 application에서 어떻게 group Id를 설정할 수 있는가? 하면은..
@KafkaListener(topics = "account", groupId = "group-id")이런식으로 Topic 명과 Group Id 를 지정하여 Consuming 하는 그룹을 만들 수 있죠
그렇다면 Group에 대해서 여러 개의 cosumer 들이 존재할 텐데요.
어떻게 Group 내에 consumer들이 살아있다고 판단할 수 있을까요?
바로 polling 제약 시간(max.poll.interval.ms) 입니다.
Group내에 consumer가 제약 시간을 넘어서 정지된다면, 정지된 consumer는 제외되고 나머지 consumer에서 polling하게 됩니다.
그러면 Group 에 대한 관리는 누가할까요?
바로 Group Coordinater 입니다.
Group Coordinater 는 Consumer Group 에 대한 관리의 책임이 있습니다.
Kafka 는 Consumer 가 동적으로 새로 생겼다가, 삭제되는 상황 ( 인스턴스가 삭제되거나 추가되는 상황 ) 에 대해서
Rebalancing 작업을 하게 되는데요. 이때 가장 중요한 역할이 바로 Group Coordinater 입니다.
Rebalancing
참 어려운 상황입니다.
어떠한 근거로 Kafka Consumer들이 Rebalancing이 이루어지게 될까요?
우리는 앞서서 HeartBeat 를 토대로 Consumer가 살아있음 혹은 죽음을 판단하였는데요.
Kafka Group 에 대해서 Consumer 개수가 변하게 된다면, Rebalancing이 이루어지게 됩니다.
또한, Topic 에 변경사항이 생긴다면 마찬가지로 Rebalancing이 이루어지게 됩니다

전체적인 흐름은
- FindCoordinator Request: Consumer Coordinator 가 Join Group 요청을 보낼 Group Coordinator를 찾는다
- JoinGroup Request: Group의 정보와 Subscription 정보를 수집하고, 리더를 선출한다
- SyncGroup Request: 리더가 그룹내에 Consumer에게 Partition을 할당하고, Group Coordinator에게 해당 정보를 보낸다
Kafka가 Rebalancing 되는 과정 중에서는 모든 Consuming( Data Fetching ) 작업이 멈춰지는
STW(Stop The World) 현상이 이루어지게 된다
그래서 Kafka 를 만든 제작자는 STW 시간을 줄이려고 무척이나 애를 쓴다 ㅎㅎ
요약하며
우리는 Kafka 를 사용한다고 하면, 정말 모르고 지나치는 것들이 많다.
설정값에 대한 부분이나 HeartBeat 에 관한 부분은 운영할 때에 있어서 정말 중요한 요소이니
한번 다시 살펴보고 운영하는 것이 정말 정말 중요하다.
참고
KafkaConsumer Client Internals
KafkaConsumer Configuration
'Developer > Stream' 카테고리의 다른 글
| Kafka Message Delivery Semantics - Exactly Once 는 정말 가능할까? (9) | 2022.05.07 |
|---|---|
| Apache Kafka Producer - Producer Deep Dive 를 해보자 (4) | 2022.04.30 |
| Apache Kafka - 메세지 브로커에 대해 알아보자 (0) | 2021.03.01 |