
들어가며

안녕하세요~! 저번 시간에는 우리가 LLM 의 기본 동작과 돌아가는 원리에 대해 살펴보았는데요
오늘은 조금 더 실무 관점에서 어떤식으로 Frontier Model 을 사용할 수 있는지 설명해보려고 합니다.
먼저 Frontier Model 이라는 용어에 대해 이해가 어려우실텐데요. 우리가 흔히 사용하는 LLM 은 크게 2가지 분류로 분류됩니다
- Frontier Model: 많은 양의 데이터로 학습되었고, 파라미터 양이 엄청나게 많아 대규모 Model 을 일컫음(ex. GPT, Claude, Gemini ...)
- Open source Model: 적은 양의 데이터로 학습되었고, 파라미터 양이 적어 무료로 오픈소스로 사용할 수 있는 Model 을 일컫음(ex. llama, gemma, gpt-oss... )
우리가 Chat Interface 에서 경험했던, 예를 들면 chatgpt.com 에서 경험했던 LLM model 들은 모두 Frontier Model 을 지칭한다고 보시면 됩니다.
특정 LLM 을 학습시키고, 완성된 Model 을 제공한다는 것은 규모가 작은 기업 혹은 기술자가 부족한 기업에서는 자체적으로 LLM 을 운영할 수 없기에, LLM 을 전문적으로 다루는 기업에서 제공한 LLM 들을 사용하여 AI application 을 누구나 쉽게 만들 수 있게 되는 것이죠.
대신에 서버 비용이라는 것이 공짜는 없기에, Token 단위의 사용량을 토대로 요금을 납부하는 대가로 사용할 수 있게 됩니다.
이번 게시글에서는 OpenAI 라는 AI platform 을 사용하여 실습을 진행하게 되므로, 이점 감안하여 실습을 진행해보세요.
OpenAI 에서는 5달러 라는 기본 요금만 납부하기만 하면 간단한 실습예제에서는 큰 Token 을 소비하지 않으니 크게 걱정 않으셔도 됩니다.
Tech stack 은 아래와 같이 진행합니다.
- language: python 3.14 sdk 기반
- project manager: uv 로 python project management
참고로 python application 의 최근 추세는 모두 uv 로 사용하는 추세로 넘어가고 있습니다.
uv 는 rust 로 작성되어 있어서 속도가 빠르고, virtual env 에 대한 관리 와 dependency 로드를 병렬로 하고 있어 매우 편리하고 빠르다고 볼 수 있습니다.
uv
An extremely fast Python package and project manager, written in Rust. Installing Trio's dependencies with a warm cache. A single tool to replace pip, pip-tools, pipx, poetry, pyenv, twine, virtualenv, and more. 10-100x faster than pip. Provides comprehens
docs.astral.sh
Text generation

가장 쉬운 것부터 시작해보려고 합니다. 특정 input 을 주었을 때 output 을 어떻게 만들 수 있을까요?
uv add opneai
uv add python-dotenv
먼저 프로젝트에 openai 라이브러리 종속성을 가져옵니다.
import os
from dotenv import load_dotenv
from openai import OpenAI
from openai.types import Reasoning
load_dotenv()
open_ai = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# chat completion api
chat_response = open_ai.chat.completions.create(
model="gpt-5-nano",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"},
],
reasoning_effort="minimal"
)
print(chat_response.choices[0].message.content)
# response api
response = open_ai.responses.create(
model="gpt-5-nano",
instructions="You are a helpful assistant.",
input="What is the capital of France?",
reasoning=Reasoning(effort="minimal")
)
print(response.output_text)
그 후에 위와 같은 코드를 간단하게 작성해보았는데요. model 은 가성비 model 인 gpt-5-nano 를 기반으로 하였습니다.
그럼 위 코드를 가동하게 되면?

Paris 라는 결과물을 주는군요!
우리는 LLM 을 이용하여 프랑스의 수도를 알려주는 기능을 구현했습니다 ^-^

그런데 조금 더 세밀하게 들여다봐야겠죠? 먼저 크게 2가지 유형으로 작성하였는데요.
대부분의 경우 chat completion API 를 사용하는 것으로 생각하시면 됩니다.
Chat Completion API 는 OpenAI 가 처음으로 제공했던 API 양식이며, 다른 Frontier model provider 들도 OpenAI 에서 제공한 양식으로 맞추려는 움직임들도 있어 누구나 쉽게 Model 을 교체하여 application 을 운영하게 되었습니다.
그러자 OpenAI 는 오로지 자기 모델에 종속적인 API 를 제공하는 것으로 스탠스를 바꾸었죠. 이는 다른 Model 사용하지 말고, OpenAI model 사용에 종속적인 application 이 되라는 것을 의미합니다.
중요한 것은 데이터를 보낼 때, role 과 content 를 지정한 것을 볼 수 있습니다.
role 은 크게 3가지 유형이 있는데요.
- system: 시스템에서 설정한 text
- user: 사용자가 질의한 text
- assistant: LLM 이 생성한 응답 text

이 3가지 데이터를 모두 고려하여, LLM 의 최종 응답이 생성된다고 보면 됩니다.
LLM 은 그 자체만으로 어떤 상태를 갖고 있지 않기 때문에, 대화형 interface 에서는 대화의 모든 이력을 데이터화 해서 전송하고, 최종적인 결과물을 얻게 되는 것이죠.
여기서 AHA 모먼트를 느끼면 좋겠네요 ^-^
사실 우리가 사용하는 모든 chat interface 를 통한 질의는 모든 대화 이력을 데이터화 하는 것이라는 것을요.
대화가 길어지면 길어질수록 LLM 이 생성하는 응답의 퀄리티가 이상해지는 현상을 볼 수도 있는데, 이는 너무 많은 Context 가 담겨있어 어떤 Text 를 생성해야될지 갈팡질팡 하는 단계라고 볼 수 있습니다.
많은 Context 가 담긴다는 것은 이전의 원리에서도 볼 수 있듯이, 수없이 많은 Vector 들이 나열되기에 서로 상충되는 Vector 데이터들이 생기거나 일관성이 없는 데이터가 생긴다면 LLM 의 output 퀄리티도 자연스럽게 떨어지게 되는것이죠
그래서 Frontier model 에서는 model 마다 허용가능한 Context window 를 안내하고 있습니다.

저희가 사용한 gpt-5-nano 모델은 최대 40만개의 Context window 라고 하는군요.
내가 질의한 내용에 대해 결과물이 만족스럽지 못한다면, 지금 나의 대화는 얼만큼의 Context window 로 넘어갈지, 대화 이력동안의 일관성은 있는지 체크해보면 좋겠군요.
이러한 Context window 의 중요성은 추후에 AI agent application 을 제작할 때, Context Engineering 이라는 주제로도 이어지게 된답니다.
Tool
LLM 이 Agentic AI 로 갈 수 있었던 배경에는 이 Tool 이 있습니다. 먼저 예시와 함께 설명해볼게요
import os
from dotenv import load_dotenv
from openai import OpenAI
from openai.types import Reasoning
load_dotenv()
open_ai = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
tools = [
{
"type": "function",
"name": "get_weather",
"description": "Get current temperature for a given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia",
}
},
"required": ["location"],
"additionalProperties": False,
},
"strict": True,
},
]
response = open_ai.responses.create(
model="gpt-5-nano",
input="What is the weather like in Paris today?",
tools=tools,
reasoning=Reasoning(effort="minimal")
)
print(response.output[1].to_json())
def get_weather(location):
# 실제 날씨 API 호출 (예시에서는 하드코딩)
return f"The current temperature in {location} is 15°C with clear skies."
# Tool 호출 구현 (response API)
for item in response.output:
if item.type == "function_call":
if item.name == "get_weather":
location = item.arguments
# 실제 날씨 API 호출 (예시에서는 하드코딩)
weather_info = get_weather(location)
# 모델에 도구 호출 결과 제공
follow_up_response = open_ai.responses.create(
model="gpt-5-nano",
input=f"The weather information for {location} is: {weather_info}",
reasoning=Reasoning(effort="minimal")
)
print(follow_up_response.output_text)
지금은 직접적으로 Tool 을 호출하고 있기에 코드가 많이 어려운데요 ㅎㅎ..
나중에는 AI agent 라이브러리를 통해 이러한 보일러플레이트 같은 코드를 직접적으로 신경쓰지는 않을 것입니다.
다음 포스팅을 기대해주세요~!
어쨌든 위 코드를 조금 쉽게 큰 그림으로 설명드리면, 이 코드는 LLM API call 을 총 2번하게 되는 코드입니다.
첫번째 호출에 대한 결과 print 는 아래와 같이 출력되고

두번째 호출에 대한 결과 print 는 아래와 같이 출력됩니다.

LLM 에게 get_weather(날씨 조회) 라는 tool 을 제공하였더니, LLM 이 tool 을 이용한 결과값을 요청하는 것이 첫번째 print 문이라고 보면 됩니다. 어떤 함수와 어떤 인자로 전달할 것인지도 결정해서 json 형태로 알려주었죠.
두번째 print 는 사용자가 요청한 질의와 함수 결과값을 최종적으로 종합하여 최종 응답을 생성한 것이라고 이해하면 됩니다.
이를 그림으로 표현하면 아래와 같습니다.
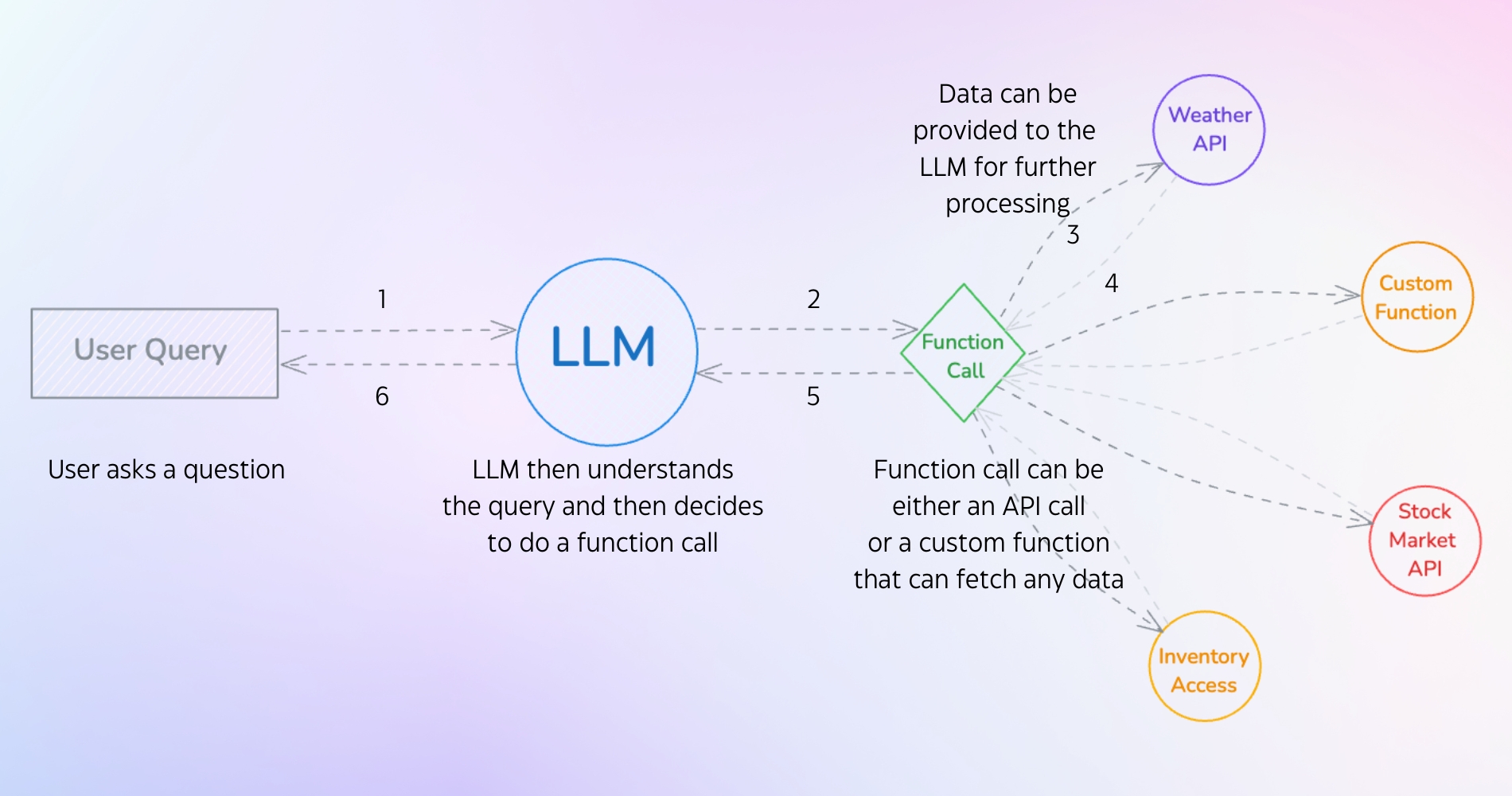
Tool 은 쉽게 이야기해서, LLM 사용할 수 있는 도구를 의미합니다. 이는 개발자가 정의한 함수를 의미하며, 로컬에서 돌린 함수 결과를 LLM 에게 전달하는 것이죠
도구는 여러가지 형태로 사용될 수 있어요.
- RAG retrieval: RAG 를 통한 질의
- API call: API 호출
- DB query: DB 질의
이 Tool 이 있기에 LLM 은 정말 무엇이든지 할 수 있게 되었습니다. 단순한 Text 예측기에서 LLM 이 직접 행동할 수 있는 기반을 갖게 되었죠.
그렇기에 모든 Model 의 Tool 표준을 정해주는 MCP(Model Context Protocol) 이 각광받게 되었습니다.
여기서도 AHA 모먼트를 느낄 수 있죠 ^-^
LLM 에게 어떤 tool 을 제공할 것인지에 따라 설계하고자하는 AI application 이 다양하게 개발될 수 있고, 어떤 일을 하게 될지 경계를 명확히 할 수 있다는 것을요.
그래서 Tool 을 정의하고, Tool 에 대한 설명을 어떻게 작성하느냐에 따라 결과물은 정말 완전히 달라질 수 있습니다.
정리하며

오늘은 크게 2가지 API 를 실전 예제와 함께 해보면서 정리해보았는데요.
Text generation 을 통해 Context window 의 중요성과 실제 데이터구조를 알아보았고,
Tool 을 통해 Tool 의 동작원리와 중요성에 대해 알아보았네요.
이제 AI Engineer 가 되기 위한 기초가 되었으니, 다음 게시글에서는 조금 심화된 과정의 Agent 로 찾아오도록 할게요!
참고문서
Developer QuickStart
'Developer > AI' 카테고리의 다른 글
| LLM 의 구조와 원리에 대해 쉽게 알아보자 (feat. llama) (0) | 2026.01.11 |
|---|